原文:https://mp.weixin.qq.com/s/Yc1-1d88aVQMn0wwzqHLqA
任何行业,只要加上AI的概念,就有了讲故事的空间。讲故事很容易,做好产品很难。
AI+ 教育亦是如此。 你以为AI在帮孩子学习,实际上AI在帮孩子偷懒。 你以为AI在给孩子讲题,实际上AI在直接给答案。
大部分人对AI教育的理解,从根上就错了。你以为拼的是大模型有多牛逼,其实根本不是。真正的AI教育,是多层技术栈的系统工程。99%的公司,连第一层都没做透。
教育的最小单元
教育说复杂很复杂,说简单也简单。
不管你用什么方法、什么工具、什么理论。
最终要把一个学生教会,本质上就是三件事:
第一,你得先知道他哪里不会。
第二,你得用他听得懂的方式,把不会的给他讲明白。
第三,你得确保他真的学会了,而且不会忘。
第一层:诊断
- 先搞清楚一个问题
为什么同样是错题本,有的越用成绩越好,有的越用越差?
因为前者在补”知识点”,后者在补”题”。
诊断,就是把”一道错题”还原成”整个知识体系漏洞”的那一步。
以前靠考试,一张卷子两小时,效率极低。孩子数学考 60 分,老师说“计算不行”,狂练三个月计算还是 60 分。真正的问题可能是三年级的“分数通分”没学好,导致后面所有涉及分数的复合题全错。补错地方了。
AI 诊断解决的就是这个问题:不用等考试,做几道题,就能精准定位出知识点里哪些没掌握,甚至追溯到是几年前的哪个前置漏洞导致的。
- 背后的技术栈:自适应的三代演进
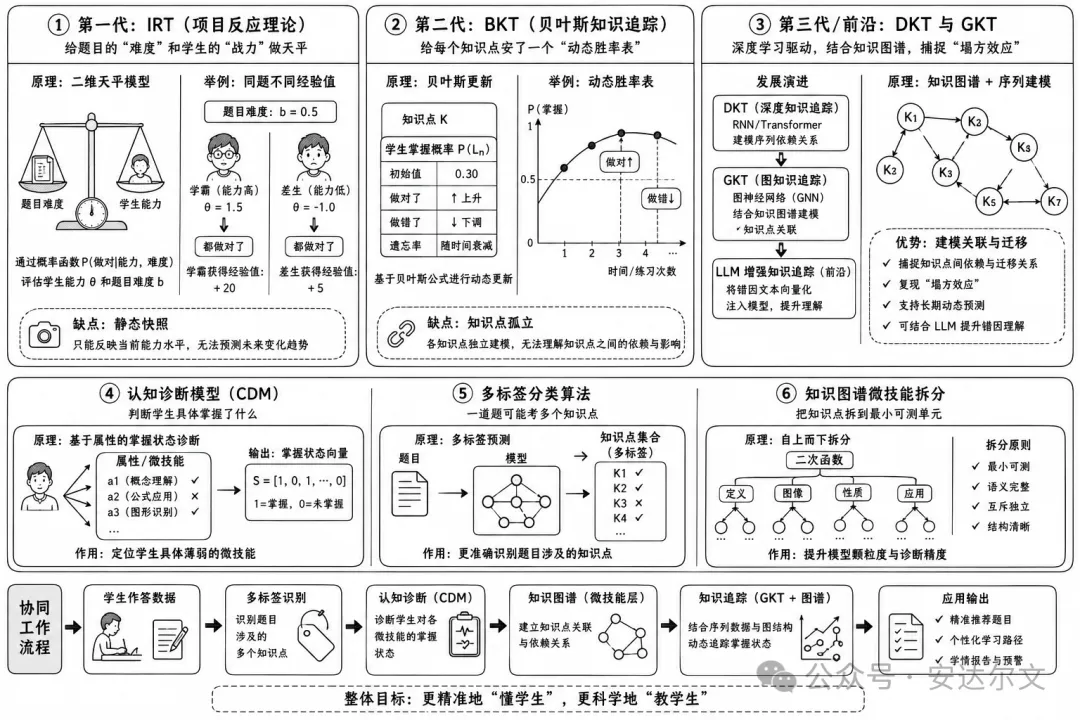
这套系统不是黑科技,是教育行业几十年的算法演进,在工程落地中主要经历了三代变化:
第一代:IRT(项目反应理论) —— 相当于给题目的“难度”和学生的“战力”做个天平。学霸和差生做对同一道题,系统给加的经验值是不一样的。缺点是它是个静态快照,只能看当前,算不出你明天的变化。
第二代:BKT(贝叶斯知识追踪) —— 20年前自适应平台的核心。它给每个知识点安了一个动态胜率表,做对概率上升,做错概率下调。缺点是太孤立,看不懂知识点之间的连带关系。
第三代/前沿:DKT(深度知识追踪)与 GKT(图知识追踪) —— 依托深度学习。因为纯 DKT 是个不可解释的黑盒,现在业界头部的落地选型是 GKT(图知识追踪)+ 显式知识图谱。最新前沿甚至在尝试用 LLM 增强知识追踪(把学生的错因文本转化为高维向量灌入模型),完美复现知识点间的“塌方效应”。
这里面最难的根本不是算法,而是底层的知识图谱拆得够不够细(也就是微技能打标)。
“一元一次方程”只拆成一个点,再牛逼的模型也没用。必须拆到“识别同类项、移项变号、去分母”这种微技能(Micro-skills)级别,诊断才能真正精准。
大部分产品所谓的个性化,闭环逻辑粗暴得搞笑:学生做错了→ 自动丢进错题本→ 下次推同类型题。这不叫个性化,这叫错题本电子化。
真正的诊断,是穿透题目表面,看到底层的认知缺陷:能清晰区分出“这道几何题做错,到底是辅助线没掌握,还是代数计算粗心”。
- 看一个真实案例
Carnegie Learning:专做 K12 数学自适应。他们的 MATHia系统,光是“一元一次方程”就拆成了 17 个微技能节点。孩子做错题,系统精准提示:“你的问题出在‘移项变号’上,当前掌握概率只有 32%。”
就诊断这一件事,他们死磕了 15 年。
这,才仅仅是第一层。第二层:教学
- 先下一个定义
直接给答案的AI,是搜题工具;会提问的AI,才是老师。
好的教学,不是把答案灌输给孩子,是一步步引导孩子自己想明白。
很多人以为,AI 讲题不就是把题目扔进 GPT,让它输出解题步骤吗?
这样做,会遭遇三个致命硬伤:
- 幻觉与超纲: 明明是小学几何题,它可能会给出高中的向量解法。
- 不讲人话: 开口就是“根据定理 3.2 我们可以得出…”,学生完全听不懂。
- 零引导: 直接给终极答案,剥夺了学生的思考过程。
真正的 AI 教学系统,孩子拍了张照上传,它不会直接给答案,而是扮演“苏格拉底”,一步步启发:
“你看看这两个三角形,有没有发现什么关系?”
“如果这两条边相等,对应的两个角是什么关系?”
- 背后的技术栈:启发式教学的五个底层模块
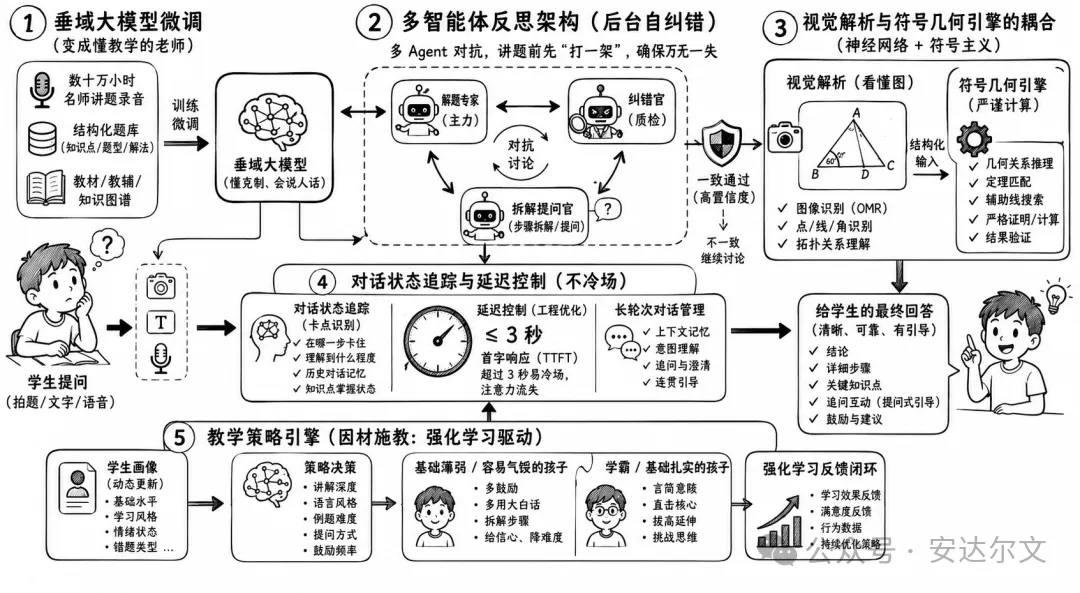
要实现这种“像好老师一样”的启发式对话,绝对不是接个 API 就能搞定的,背后是一整套复杂的工程栈:
垂域大模型微调(说人话): 通用模型是不懂教学规律的。你得用数十万小时的名师讲题录音、结构化题库去专门调教它,把模型从一个“冷冰冰的学者”变成一个“懂克制、会说人话的老师”。
多智能体反思架构(后台自纠错): 单一模型讲题很容易陷入“自圆其说”的幻觉——自己算错了还觉得自己特有道理。成熟的产品在线下会跑多 Agent 对抗,一个负责解题,一个扮演“纠错官”,一个负责把步骤拆成提问。在把话发给学生之前,它们在后台先“打一架”,确保万无一失。
视觉解析与符号几何引擎的耦合(神经网络+符号主义): 理科的几何题是重灾区。光靠大模型盲猜辅助线,准确率是不稳定的。必须通过视觉识别(OMR)看懂图形的拓扑关系,再把关系输入给确定的几何解题引擎去算,用机器的严谨去补足大模型的“感性”。
对话状态追踪与延迟控制(不冷场): 讲题是长轮次对话。系统不仅要精准追踪学生“卡在哪一步”,更要在工程上把首字响应延迟(TTFT)压到 3 秒以内。在教学中,超过 3 秒的停顿冷场,孩子的注意力就彻底散了。
教学策略引擎(因材施教): 这是一个强化学习问题。系统能从数据里学会:对基础薄弱、容易气馁的孩子多鼓励、多用大白话;对学霸则言简意赅,直接点拨核心。
- 看一组真实数据
宾大沃顿商学院曾针对近 1000 名高中生做过一项严格的随机对照实验(RCT),他们被分为三组:
- 第一组: 传统教学,不使用任何 AI。
- 第二组: 使用普通 ChatGPT(直接搜答案)。
- 第三组: 使用加了教学护栏的 AI Tutor(引导式讲题)。
实验结果让人警醒:
- 普通 ChatGPT 组: 刷题练习时成绩暴涨 48%,但到了独立正式考试,成绩反而比不用 AI 的普通学生还要低 17%(学生对直接要答案产生了严重的心理依赖)。
- 引导式 AI Tutor 组: 练习成绩暴涨 127%,正式考试成绩也获得了显著的实质性提升。
差的不是大模型,是大模型内外的多层教学策略和引导护栏。
这,是第二层。
第三层:练习
- 再理解一个现象
讲懂了,不代表学会了。学会了,不代表不会忘。在传统教育里,练习和复习才是真正拉开学生差距的地方。
很多 AI 教育产品在“讲完题”之后就撒手不管了,这就是它们没用的根源——它们只做了“输入”,没做“内化”。
同样是学一个知识点:
- 有的孩子可能学一遍就记住了。
- 有的孩子可能写了十遍,过三天还是忘。 这真不是孩子笨,而是刷题的节奏、复习的时机完全搞错了。
好的 AI 练习系统,就像一个全天候盯着孩子的私教。它会死死记住你家孩子哪个知识点容易忘,在快要遗忘的临界点突然推一道题过来巩固,直到真正变成长期记忆。
- 背后的技术栈:自适应练习的四大内核
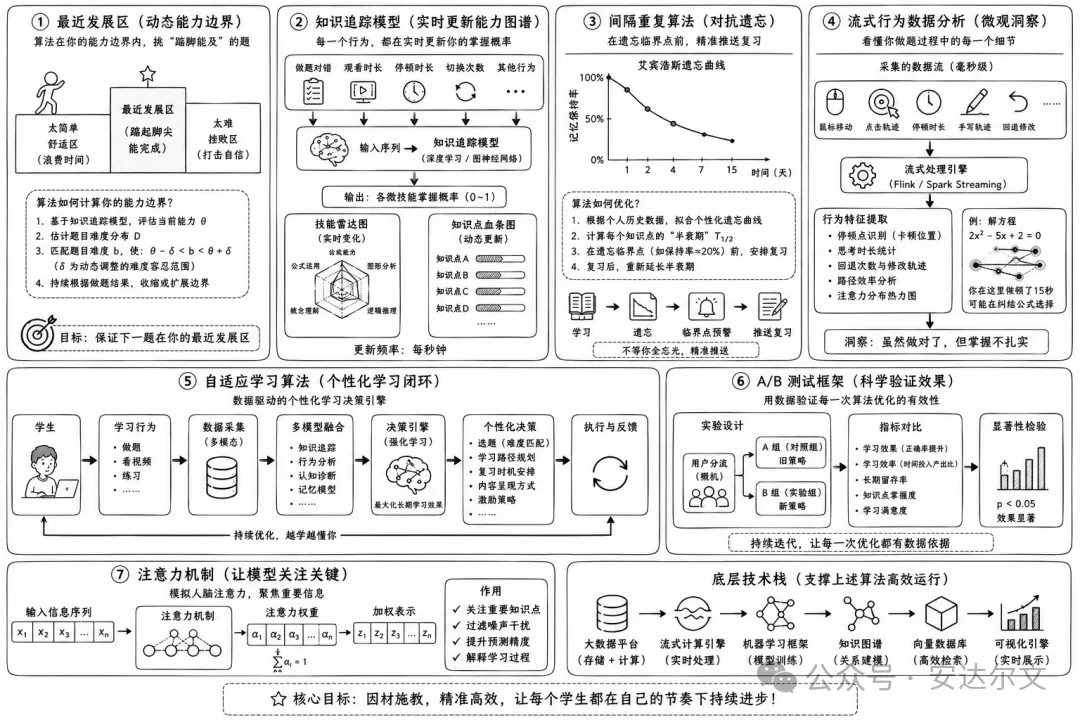
这一层外行看不见,也吹不了牛。它在底层其实是一套纯粹的数据闭环,通过算法把刷题变成了“打游戏”:
最近发展区: 算法在给学生挑题时,既不挑太难的(打击自信),也不挑太简单的(浪费时间)。它永远在计算你的能力边界,保证下一道题刚好在你的“最近发展区”——就像打游戏,关卡难度刚好是你踮起脚尖、集中精神就能打过的“精英怪”。
知识追踪模型: 这是个强化学习问题。学生每做一道题、每看一分钟视频,甚至在题目上停顿了十秒钟,数据都会被喂进模型,实时更新他对每个微技能的掌握概率。在系统后台,学生的“技能雷达图”和“知识点血条”每秒钟都在变。
间隔重复算法: 大家都听过艾宾浩斯遗忘曲线,但怎么用好它?算法会根据你前几次的做题速度和对错,精准算出你对这个公式的“半衰期”。不等你全忘光,在记忆即将断裂的那个早晨,它会准时把复习题推到你面前。
流式行为数据分析: 厉害的系统连学生做题时鼠标的停顿、手写笔的回退、修改轨迹都能捕获。你在这里卡了 15 秒,系统就知道你虽然最后做对了,但其实是在纠结两个公式,掌握得并不扎实。
- 看不见的基本功
练习这一层,在产品发布会上最难吹牛。因为你没办法在 PPT 上跟观众吹:“我们的间隔重复算法让复习效率优化了 2%”,观众听了只想打哈欠。
大家都喜欢吹“我们的大模型参数有多少亿”、“我们的生成速度有多快”。但真正决定提分效果的,往往就是这些看不见的、极其枯燥的、需要用真金白银砸数据去跑 A/B 测试的算法细节。
AI 教育是个真正的慢生意。你得沉下心来,一年一年地跑数据,一毫米一毫米地磨细节。这里,没有任何捷径可走。
这,是第三层。
AI+教育的三个闭环
市面上 99% 融了钱、开了发布会的 AI 教育产品,在接下来的两三年里大概率会无声无息地死掉。
不用看它的大模型参数有多高,也不用听它的营销故事有多性感。在商业落地和用户留存的生死线上,你只需要用三个闭环指标去穿透它:
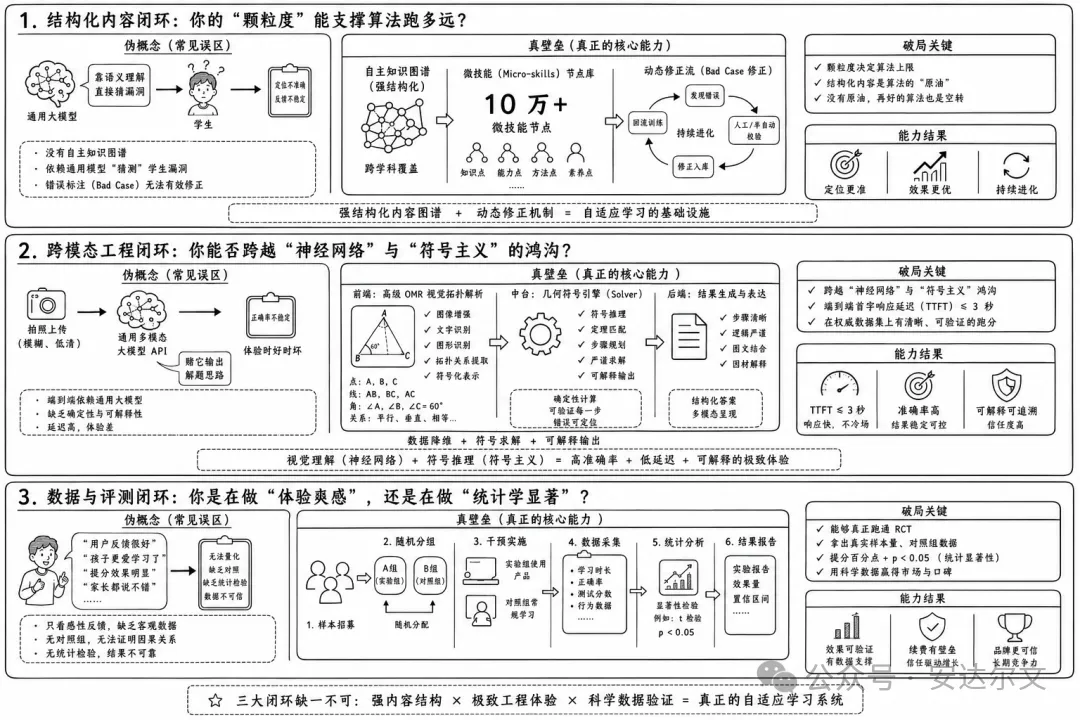
1. 结构化内容闭环:你的“颗粒度”能支撑算法跑多远?
如果一个项目宣称自己用的是大模型自适应,你只需要看他的知识图谱打标精度。
伪概念: 连自主知识图谱都没有,指望大模型靠语义理解直接去猜学生的漏洞。
真壁垒: 能够跨学科拆解出 10 万个以上的微技能(Micro-skills)节点,并且有底气掏出针对 Bad Case(错误标注)的动态修正流。算法只是发动机,强结构化的内容图谱才是原油。没有原油,再好的算法也是空转。
2. 跨模态工程闭环:你能否跨越“神经网络”与“符号主义”的鸿沟?
K12 教育(尤其是数理化)是重度依赖图形、公式和长文本推理的。
伪概念: 拍一张模糊的几何题照片,直接调用一个通用多模态大模型 API,然后赌它输出解题思路的正确率。
真壁垒: 前端靠高级 OMR 进行视觉拓扑解析,后端必须将数据降维,灌入确定的几何符号引擎(Solver)。能清晰报出自身在权威数据集上的跑分,并把端到端首字响应延迟(TTFT)卡在用户注意力分散之前。跨不过这道工程坎,产品体验就是灾难。
3. 数据与评测闭环:你是在做“体验爽感”,还是在做“统计学显著”?
伪概念: 拿不出任何严谨的数据,只会用“用户反馈很好”、“孩子更爱学习了”这种无法量化的感性词汇来掩盖留存率的拉胯。
真壁垒: 能够真正跑通随机对照实验(RCT)。敢于把真实的样本量、对照组数据、提分百分点以及 $p < 0.05$(统计显著性)的实验报告拍在桌子上。只有通过了统计学检验的产品,才具备真正的续费壁垒。
这三个闭环,就是大模型浪潮退去后,AI+教育真正应该思考的方向。
AI 从不负责凭空创造教育奇迹,它只负责把那些对教育规律的纯粹敬畏、对教育细节的工匠雕琢,精准地转化为因材施教的生产力。
后记
每一次技术浪潮来临,行业都在争论“AI 会不会让老师失业”。
这个讨论,从一开始就失焦了。
在过去很多年的时间里,我们的学校和机构被迫采用了“流水线”式的工业化教育:一个老师,带着 50 个学生,用统一的教材,用同样的进度,刷同样的题。
在这种模式下,老师被迫变成了“讲题机器”和“批改工具”,他们 70% 的精力都在做毫无技术含量的机械重复。而学生,则被迫抹平了个性,去适应流水线的速度。
AI 教育真正的变革,不是消灭老师,而是要终结这种反人性的工业化流水线。
它把老师从“讲题机器”的苦役中解放了出来。
省下来的时间,老师终于可以去履行教育最本源的职责: 去观察那个坐在角落里、内向不敢举手的孩子; 去和最近状态下滑的学生在操场上散散步、聊聊天; 去点燃孩子的内驱力,去培养他们的批判性思维和创造力。
AI 负责把知识“降维传输”,老师负责把灵魂“升维点燃”。
这场变革才刚刚开始。
那些只会念 PPT、只会逼学生机械刷题的“生产线工人”,确实该面临转型了;
而那些真正有温度、有信仰的教育者,又怎么会轻易被AI替代。