因为项目需要,需要让CEF支持播放h.264和mp3视频,但从CEF官网上下载得到的并不支持, 需要自己进行重新编译;在经常大量的搜索后发现, 没有人经常性的编译CEF,有的只是之前的比较老的版本,所以决定自己编译。下面展示成果:
在决定要自己进行编译后,真的是一脸茫然,不知道该如何下手,在花了大量的时间,阅读了大量的材料后,把我的经验写下来,让后来者能少走弯路。
开始
在CEF的官方仓库上有关于如何进行编译的WIKI, 当前的地址是这里,有做了详细的说明。
编译CEF的过程可以手动进行,也有自动化的编译脚本,作为一个只要结果,不要过程的人,我选择了自动化编译 。但在进行自动化编译前,需要把编译系统搭建好,windows下编译的要求:

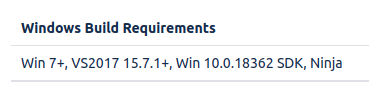
需要windows 7 以上的系统(我选择了windows server 2016数据中心版), Visual Studio 2017 以上,安装windows SDK 10.0.18362 版本 (千万别要安装其他版本,我就是浪费了好几个小时的时间),Ninja( 这个就不用我们安装,自动化工具会自动安装);
硬件要求:最少8G内存(推荐32G以上),至少90G以上的剩余硬盘空间,要有足够快的网速(100Mbps以上), 足够快的CPU(2.4Ghz 16线程),最好是SSD。
这个要求太高了, 我自己没这么好的电脑,而且只要编译一次,最多3、4天时间,我决定购买阿里云服务器(建议买香港的服务器,因为你知道的一些原因,国内很多文件下载不下来), 本来想用DigitalOcean的,因为没有流量费,还便宜, 但看了下来, 他们不提供windows系统,徒耐何?
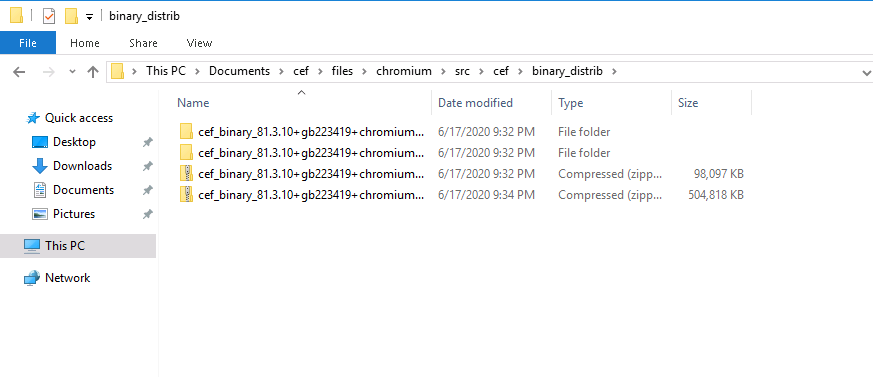
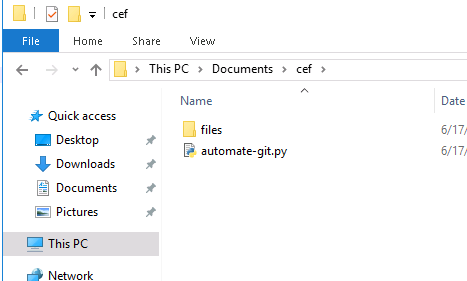
等系统购买好后,在document目录下创建一个cef文件夹,先下载安装python(3点几版本就ok, 记得安装的时候要勾上把python加入到系统环境变量), 从这里下载自动化编译脚本,如下放置,并在该目录下创建一个files文件夹,用于存放之后的文件
然后打开cmd, 运行以下命令:
C:\Users\Administrator\Documents\cef>python automate-git.py --download-dir=C:\Users\Administrator\Documents\cef\files --branch=4044 --no-debug-build
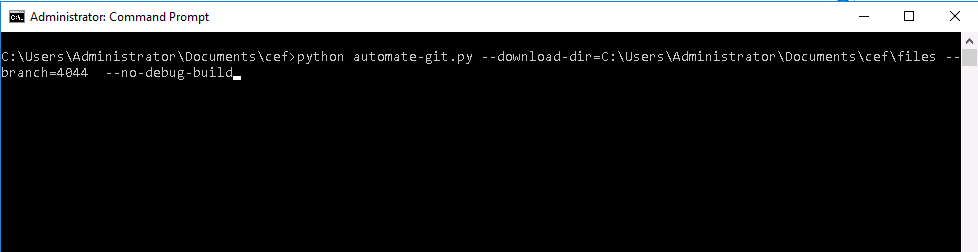
其中–download-dir表示用哪个文件夹来存储下载的文件, –brand表示要编译的哪一个cef的分支,这个编号可以从这里获取
然后等待脚本下载各种工具(包括git, Ninja)和源码(chroium源码非常大, 十多个G, 这个是下载时间最长的), 之后的目录如下:
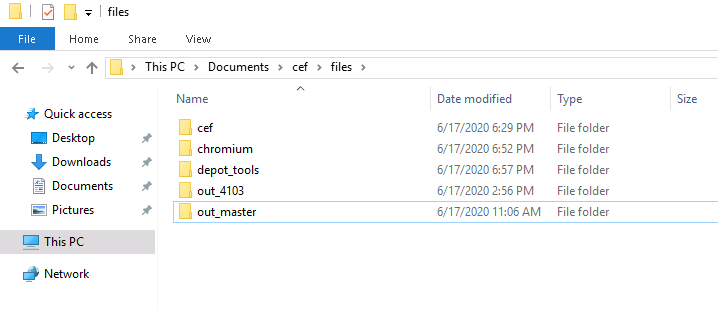 上面的out_打头的文件夹是最后编译生成的
上面的out_打头的文件夹是最后编译生成的
在这之前如果你没有安装好visual studio 2019(文档要求2017以上,我选择了2019), 等源码下载完成后编译时会报错,不用怕, 这个时候安装它,安装完成之后,要修改几个文件,修改(建议安装Notepad++来修改,好用)这几个文件的目的是把音视频播放的功能加进去:
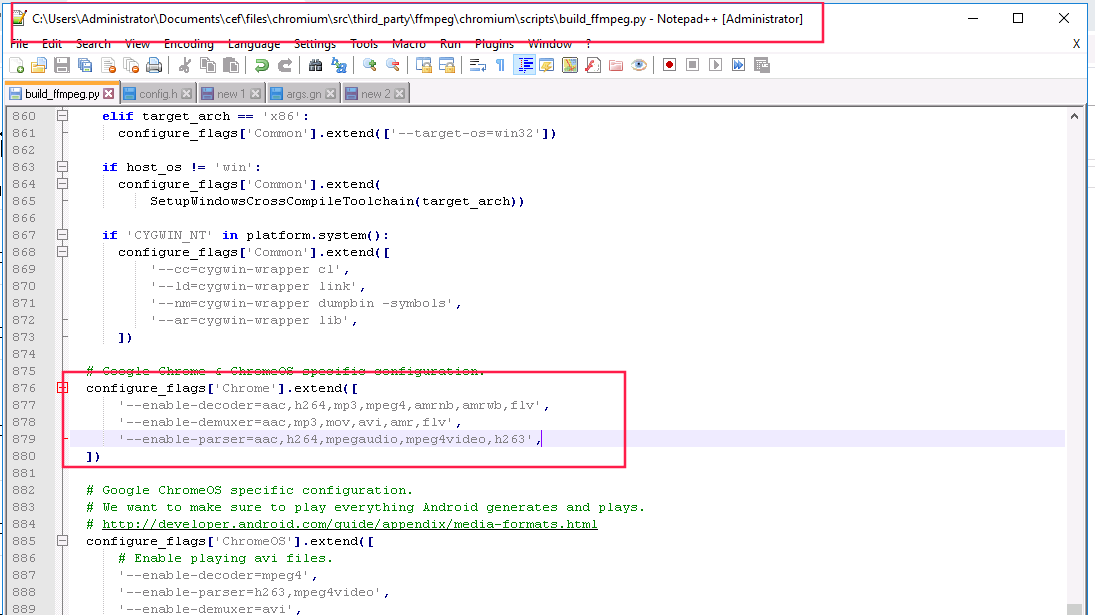
第一个文件:C:\Users\Administrator\Documents\cef\files\chromium\src\third_party\ffmpeg\chromium\scripts\build_ffmpeg.py
找到 configure_flags['Chrome'] 修改成以下内容:
configure_flags['Chrome'].extend([
'--enable-decoder=aac,h264,mp3,mpeg4,amrnb,amrwb,flv',
'--enable-demuxer=aac,mp3,mov,avi,amr,flv',
'--enable-parser=aac,h264,mpegaudio,mpeg4video,h263',
])
第二个要修改的文件是一个头文件
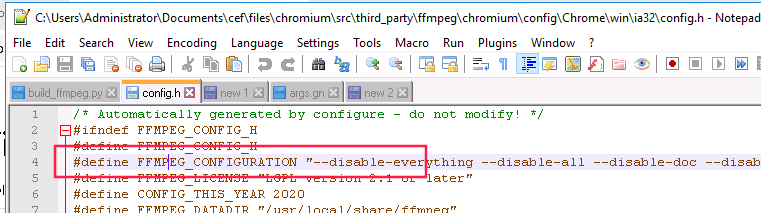
C:\Users\Administrator\Documents\cef\files\chromium\src\third_party\ffmpeg\chromium\config\Chrome\win\ia32\config.h
我这里修改的是32位的目录(ia32), 如果你是要编译64位的, 也要把x64的一起修改了
要第4行的注释去掉,修改下面这样:
define FFMPEG_CONFIGURATION "--disable-everything --disable-all --disable-doc --disable-htmlpages --disable-manpages --disable-podpages --disable-txtpages --disable-static --enable-avcodec --enable-avformat --enable-avutil --enable-fft --enable-rdft --enable-static --enable-libopus --disable-debug --disable-bzlib --disable-error-resilience --disable-iconv --disable-lzo --disable-network --disable-schannel --disable-sdl2 --disable-symver --disable-xlib --disable-zlib --disable-securetransport --disable-faan --disable-alsa --disable-autodetect --enable-decoder='vorbis,libopus,flac' --enable-decoder='pcm_u8,pcm_s16le,pcm_s24le,pcm_s32le,pcm_f32le,mp3' --enable-decoder='pcm_s16be,pcm_s24be,pcm_mulaw,pcm_alaw' --enable-demuxer='ogg,matroska,wav,flac,mp3,mov' --enable-parser='opus,vorbis,flac,mpegaudio,vp9' --extra-cflags=-I/usr/local/google/home/jrummell/chromium/src/third_party/opus/src/include --disable-linux-perf --x86asmexe=nasm --optflags='\"-O2\"' --enable-decoder='theora,vp8' --enable-parser='vp3,vp8' --toolchain=msvc --extra-cflags=-I/usr/local/google/home/jrummell/chromium/src/third_party/ffmpeg/chromium/include/win --enable-cross-compile --cc=clang-cl --ld=lld-link --nm=llvm-nm --ar=llvm-ar --extra-cflags=-O2 --extra-cflags=-m32 --extra-cflags=-imsvc/usr/local/google/home/jrummell/chromium/src/third_party/ffmpeg/../depot_tools/win_toolchain/vs_files/9ff60e43ba91947baca460d0ca3b1b980c3a2c23/win_sdk/Include/10.0.18362.0/um --extra-cflags=-imsvc/usr/local/google/home/jrummell/chromium/src/third_party/ffmpeg/../depot_tools/win_toolchain/vs_files/9ff60e43ba91947baca460d0ca3b1b980c3a2c23/win_sdk/Include/10.0.18362.0/shared --extra-cflags=-imsvc/usr/local/google/home/jrummell/chromium/src/third_party/ffmpeg/../depot_tools/win_toolchain/vs_files/9ff60e43ba91947baca460d0ca3b1b980c3a2c23/win_sdk/Include/10.0.18362.0/winrt --extra-cflags=-imsvc/usr/local/google/home/jrummell/chromium/src/third_party/ffmpeg/../depot_tools/win_toolchain/vs_files/9ff60e43ba91947baca460d0ca3b1b980c3a2c23/win_sdk/Include/10.0.18362.0/ucrt --extra-cflags=-imsvc/usr/local/google/home/jrummell/chromium/src/third_party/ffmpeg/../depot_tools/win_toolchain/vs_files/9ff60e43ba91947baca460d0ca3b1b980c3a2c23/VC/Tools/MSVC/14.23.28105/include --extra-cflags=-imsvc/usr/local/google/home/jrummell/chromium/src/third_party/ffmpeg/../depot_tools/win_toolchain/vs_files/9ff60e43ba91947baca460d0ca3b1b980c3a2c23/VC/Tools/MSVC/14.23.28105/atlmfc/include --extra-ldflags='-libpath:/usr/local/google/home/jrummell/chromium/src/third_party/depot_tools/win_toolchain/vs_files/9ff60e43ba91947baca460d0ca3b1b980c3a2c23/VC/Tools/MSVC/14.23.28105/atlmfc/lib/x86' --extra-ldflags='-libpath:/usr/local/google/home/jrummell/chromium/src/third_party/depot_tools/win_toolchain/vs_files/9ff60e43ba91947baca460d0ca3b1b980c3a2c23/win_sdk/Lib/10.0.18362.0/ucrt/x86' --extra-ldflags='-libpath:/usr/local/google/home/jrummell/chromium/src/third_party/depot_tools/win_toolchain/vs_files/9ff60e43ba91947baca460d0ca3b1b980c3a2c23/win_sdk/Lib/10.0.18362.0/um/x86' --extra-ldflags='-libpath:/usr/local/google/home/jrummell/chromium/src/third_party/depot_tools/win_toolchain/vs_files/9ff60e43ba91947baca460d0ca3b1b980c3a2c23/VC/Tools/MSVC/14.23.28105/lib/x86' --enable-decoder='aac,h264' --enable-demuxer=aac --enable-parser='aac,h264' -enable-decoder=’rv10,rv20,rv30,rv40,cook,h263,h263i,mpeg4,msmpeg4v1,msmpeg4v2,msmpeg4v3,amrnb,amrwb,ac3,flv’ -enable-demuxer=’rm,mpegvideo,avi,avisynth,h263,aac,amr,ac3,flv,mpegts,mpegtsraw’ -enable-parser=’mpegvideo,rv30,rv40,h263,mpeg4video,ac3′"
 修改config.h文件
修改config.h文件
然后修改最后一个文件:
C:\Users\Administrator\Documents\cef\files\out_master\Debug_GN_x86\args.gn
在文件的末尾加上两行
proprietary_codecs=true
ffmpeg_branding="Chrome"
然后再次执行编译命令:
C:\Users\Administrator\Documents\cef>python automate-git.py --download-dir=C:\Users\Administrator\Documents\cef\files --branch=4044 --no-debug-build
然后坐着等吧, 如果一切顺利,几个小时后就可以拿到编译的文件了, 最后的libcef.dll比没有视频的大了好几M。
这也是我第一次体验,一个代码的编译要花5、6个小时的,之前我写delphi, 写go, 那都是秒级的。
最后,如果你不想自己也走一次这个过程(实在是时间长, 还不便宜), 我附上我的成果:
点这里下载:cef_binary_81.3.10+gb223419+chromium-81.0.4044.138_windows32.zip
对了,我们公司招人, 如有兴趣,联系我-
链接: https://pan.baidu.com/s/1VVQ2SANZ28VdW0cv6aWFfw 密码: h73a